[KT AIVLE 3기] 이변량분석
산점도
두 숫자형 변수의 관계를 나타내는 그래프
# 직선이 중요 -> 무슨 의미일까? 차차 알아가보자.
환경 준비
라이브러리를 먼저 불러오자.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns이번에는 뉴욕 공기 오염도 데이터셋을 사용해보자.
air = pd.read_csv('https://raw.githubusercontent.com/DA4BAM/dataset/master/air2.csv')
air['Date'] = pd.to_datetime(air['Date'])
산점도 플롯
plt.scatter('Temp', 'Ozone', data = air)
#plt.scatter(air['Temp'], air['Ozone'])
#sns.scatterplot(x='Temp', y='Ozone', data = air)
plt.xlabel('Temp')
plt.ylabel('Ozone')
plt.show()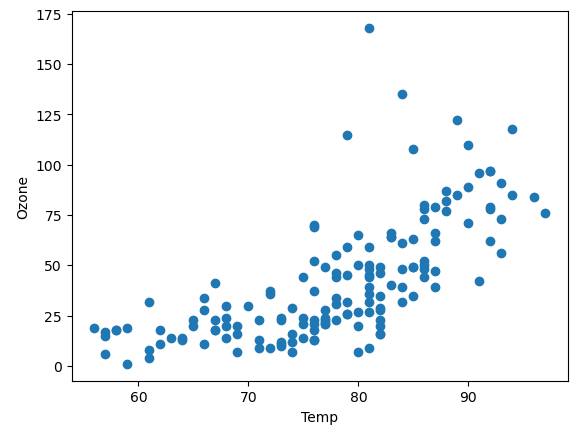
산점도에서 무엇을 확인할 수 있을까? 잘 보면... 온도가 증가할 때마다 오존 농도도 대체로 증가하는 '직선'을 볼 수 있다.
강한 관계, 약한 관계
산점도에서 강한 관계라는 것은 얼마나 직선에 모여 있는지, x - y 의 관계를 얼마나 직선으로 잘 설명할 수가 있는지를 의미한다.
하지만 일일이 scatter 사용해서 산점도 하나씩 보고 직선 관계 살펴보고... -> 귀찮고 시간도 걸린다 -> pairplot
sns.pairplot(air)
plt.show()
# 산점도와 각각의 히스토그램을 함께 보여주는 jointplot
sns.jointplot(x='Temp', y='Ozone', data = air)
plt.show()
# regplot
sns.regplot(x='Temp', y='Ozone', data = air)
plt.show()
하지만, 눈으로 그래프를 보면서 관계를 파악하고 차이를 분석하는 것은 쉬운 일이 아니다.
우리에겐 관계를 숫자로 알려주는 '상관계수'가 필요하고, 이 상관계수가 유의미한지를 검정하는 '상관분석'이 필요하다.
상관계수(Correlation)
상관계수는 'r'로 표현한다. -1~1 사이의 값을 가지며, |1|에 가까울 수록 강한 상관관계를 나타낸다.
scipy 모듈을 활용하여 상관분석을 해보자.
import scipy.stats as spstspst.pearsonr(air['Temp'], air['Ozone'])
# PearsonRResult(statistic=0.6833717861490114, pvalue=2.197769800200274e-22)결과가 tuple 형태로 나오는데, [0]은 상관계수, [1]은 p-value를 의미한다.
p-value
상관계수가 유의미한지 판단하는 숫자
p-value < 0.05 -> 두 변수 간에 관계가 있다. = 상관계수가 의미있다.
p-value >= 0.05 -> 두 변수 간에 관계가 없다. = 상관계수가 의미없다.
한꺼번에 상관계수 구하기
df.corr() 로 구할 수 있다.
air.corr()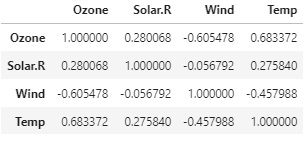
- 같은 변수끼리는 당연히 상관계수가 1이 나온다 = 의미없다.
- 상관계수의 절댓값이 1에 가까울수록 강한 상관관계 -> Ozone-Temp가 가장 강한 상관관계
- 상관계수의 절댓값이 0에 가까울수록 약한 상관관계 -> Solar.R-Wind가 가장 약한 상관관계
# 양의 상관관계 / 음의 상관관계
간단히 설명하면 A 증가하면 B도 증가 -> 양
A 증가하면 B 감소 -> 음
++ 상관계수를 heatmap으로 시각화
plt.figure(figsize = (4, 4))
sns.heatmap(air.corr(),
annot = True, # corr 표기 여부
fmt = '.2f', # 숫자 형식: 소수점 2자리까지 표기
cmap = 'RdYlBu_r', # 칼라맵
vmin = -1, vmax = 1) # 값 최소~최대 범위
plt.show()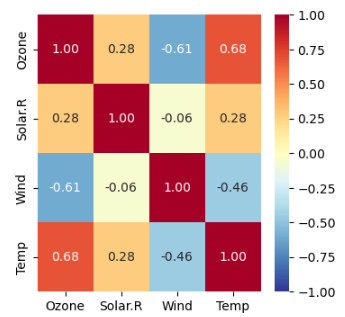
이변량분석 범주 - 숫자
이전에 사용했던 타이타닉 데이터셋으로 실습을 해보자.
준비 단계
라이브러리 및 데이터를 불러오자.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import scipy.stats as spst
titanic = pd.read_csv('https://raw.githubusercontent.com/DA4BAM/dataset/master/titanic.0.csv')
titanic.info()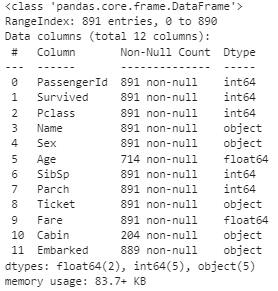
시각화
시각화를 통해 데이터를 한눈에 보고 비교해보자.
sns.barplot(x="Sex", y="Age", data=titanic)
plt.grid()
plt.show()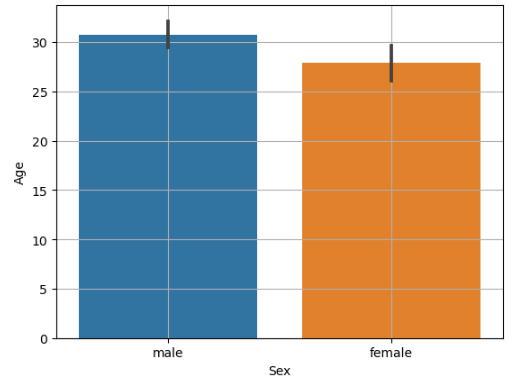
수치화
t - test
NaN을 제외한 데이터들로 계산을 해야한다.
A -> B 의 관계에서, 두 집단의 평균을 비교하여 두 변수간에 관련이 있는지를 확인하는 것
- t 통계량: 두 평균의 차이를 표준오차로 나눈 값 ( =. 두 평균의 차이) -> 일반적으로 t 값이 |2|보다 크면 차이(관련)가 있다.
- 데이터 준비(NaN 제외)
가설: 성별 별로 생존여부에 차이가 있을 것이다.
isna()로 NaN이 있는지 확인 + sum()으로 NaN 개수 총합을 구한다.
titanic.isna().sum()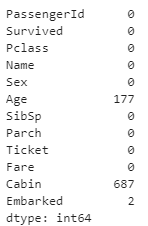
우리는 Survived, Sex를 쓸 거니까 NaN 딱히 제외 안해도 되겠군.
- 데이터를 두 그룹으로 저장 및 결과 확인
male = titanic.loc[titanic['Sex']=='male', 'Survived']
female = titanic.loc[titanic['Sex']=='female', 'Survived']spst.ttest_ind(male, female)
pvalue가 0.5 미만 -> 상관계수 의미 O + t값 |2| 이상 -> 성별에 따라 생존여부에 차이가 있다.
anova(ANalysis Of VAriance): 분산 분석
위에서 두 집단 간의 차이를 비교하는 방법을 배웠다. 그렇다면 여러 집단 간의 차이는 어떻게 비교할 수 있을까?
F 통계량 = (집단 간 분산) / (집단 내 분산) = (전체 평균 - 각 집단 평균) / (각 집단의 평균 - 개별 값)
F 통계량 값이 대략 2~3 이상이면 차이가 있다고 판단한다.
sns.barplot(x="Pclass", y="Fare", data=titanic) # P class: 3 범주 -> Fare
plt.grid()
plt.show()당연히 좌석 클래스별로 운임 차이가 있다는 것을 알지만, 이해를 돕기 위해서...
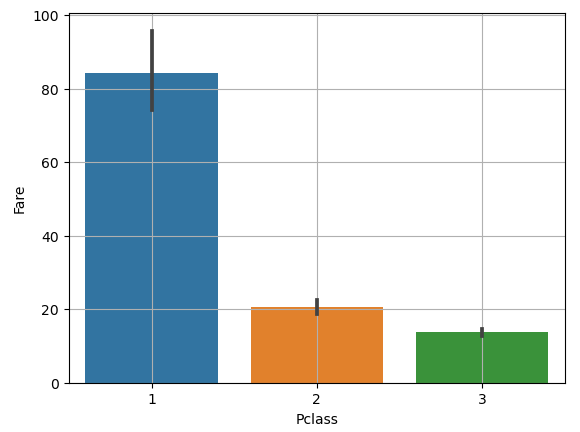
이제 한번 가설을 세우고 확인해보자.
가설: 승선지역에 따라 나이에 차이가 있을 것이다.
# NaN 제외
temp = titanic.loc[(titanic['Age'].notnull()) & (titanic['Embarked'].notnull())]
s = temp.loc[temp.Embarked == 'S', 'Age']
c = temp.loc[temp.Embarked == 'C', 'Age']
q = temp.loc[temp.Embarked == 'Q', 'Age']
spst.f_oneway(s, c, q)
상관계수가 의미없으므로 = 관계가 없다.
'AIVLE' 카테고리의 다른 글
| [AIVLE] 딥러닝 - keras 기초 (0) | 2023.02.27 |
|---|---|
| [AIVLE] 머신러닝 (0) | 2023.02.24 |
| [KT AIVLE 3기] 단변량분석 (0) | 2023.02.09 |
| [KT AIVLE 3기] 데이터 시각화 (0) | 2023.02.09 |
| [KT AIVLE 3기] 시계열 데이터 처리 (0) | 2023.02.09 |



