[AIVLE] 딥러닝 - keras 기초
프레임워크 선택 - Tensorflow(Keras)
보통 Tensorflow, Pytorch 둘 중 하나 쓰는데 나는 파이토치가 익숙하지만, 수업에서는 tensorflow의 keras를 써서 더 잘 됐다는 생각이 들었다. tensorflow도 연습을 할 수 있어서 일석이조다.
Linear Regression / Logistic Regression
import tensorflow as tf
from tensorflow import keras
import numpy as np기본 라이브러리 불러오기 - colab을 사용하면 별도의 설치 필요 없이 코드로 불러와 사용할 수 있다.
x = np.array(range(30))
y = x * 2 - 10
print(x)
print(y)
x값을 토대로 y를 예측하는 간단한 선형 회귀 모델을 생성해보자.
이 때, input은 x이고 output은 y이고, shape는 둘 다 (20,) 이다.
이제 keras로 모델을 생성해보자.
keras.backend.clear_session() # 이전 모델 세션 클리어
# 모델 생성
model = keras.models.Sequential()
# 모델 조립(인풋 사이즈 등 설정)
model.add(keras.layers.Input(shape=(1,))) # 입력 데이터의 모양을 model에 알려주는 것
model.add(keras.layers.Dense(1)) # 입력과 출력을 연결해주는 Dense
# 모델 컴파일
model.compile(loss = 'mse', optimizer = 'adam')내가 생성하고 싶은 모델은 인풋 데이터가 1개고 출력값도 하나인(여러 class가 아닌) 모델이다.
따라서 Input과 Dense 모두 1
이제 모델을 학습시켜보자.
model.fit(x, y, epochs=10, verbose=1)
loss가 떨어지긴 하는데, 엄청난 로스의 모델 = 망한..모델? 임을 확인할 수 있다.
import matplotlib.pyplot as plt
plt.plot(y)
plt.plot(model.predict(x), color = 'r')
plt.show()결과를 한번 플롯해보자, 파랑이 우리가 원하는 값, 빨강이 모델이 예측한 값이다

아무튼 이렇게 첫 케라스 모델을 생성해봤다.
sklearn 데이터 불러와서 사용해보기
from sklearn.datasets import load_boston
boston = load_boston()
x = boston.data
y = boston.target제공되는 데이터셋을 이런 식으로 불러와 학습에 사용할 수 있다. 정말 좋은 세상...
이제 이 데이터의 shape을 보면서 모델을 설계해보자.
x.shape # (506, 13)
y.shape # (506,)
Input shape를 13을 줘야겠구나. 를 생각해줘야 한다.
keras.backend.clear_session()
model = keras.models.Sequential()
model.add(keras.layers.Input(shape = (13,)))
model.add(keras.layers.Dense(1))
model.compile(loss='mse', optimizer='adam')model.fit(x, y, epochs = 100, verbose = 1)
결과 시각화는 다음과 같다.
import matplotlib.pyplot as plt
plt.plot(y, color = 'cyan')
plt.plot(model.predict(x), color = 'pink')
plt.show()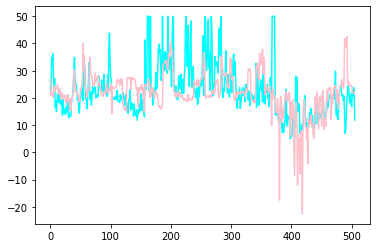
뭐 결과는 안좋지만.. 텐서플로우 코드 익숙해지는데 의의를 두자. 나중 되면 엄청 결과 좋은 모델도 많이 할거니까.
Binary Classifier
이진 분류기 - sigmoid 사용하는 이진 분류기를 설계해보자.
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
x = cancer.data
y = cancer.target
x.shape, y.shape # (569,30) (569,)설계한 모델은 다음과 같다.
keras.backend.clear_session()
model = keras.models.Sequential()
#조립
model.add(keras.layers.Input(shape=(30,)))
model.add(keras.layers.Dense(1, activation = 'sigmoid'))
model.compile(loss = 'binary_crossentropy', metrics = ['accuracy'], optimizer = keras.optimizers.Adam())model.fit(x, y, epochs = 100, verbose = 1)
Multiclass
그럼 붓꽃 종류 분류와 같은 멀티클래스 분류는 어떻게 설계할 수 있을까?
from sklearn.datasets import load_iris
iris = load_iris()
x = iris.data
y = iris.target
x.shape, y.shape #(150,4) (150, )약간의 전처리가 필요하다.
iris.target_names # array(['setosa', 'versicolor', 'virginica'], dtype='<U10')
y = to_categorical(y, 3) # y를 [0, 0, 1] 형태로 변경keras.backend.clear_session()
model = keras.models.Sequential()
model.add(keras.layers.Input(shape = (4,)))
model.add(keras.layers.Dense(3, activation = 'softmax'))
model.compile(loss = 'categorical_crossentropy', metrics = ['accuracy'], optimizer = 'adam')
model.summary()
model.fit(x, y, epochs = 100, verbose = 1)
'AIVLE' 카테고리의 다른 글
| [AIVLE] 딥러닝 3일차(CIFAR) + Functional API (1) | 2023.03.02 |
|---|---|
| [AIVLE] 딥러닝 2일차 (0) | 2023.02.28 |
| [AIVLE] 머신러닝 (0) | 2023.02.24 |
| [KT AIVLE 3기] 이변량분석 (0) | 2023.02.10 |
| [KT AIVLE 3기] 단변량분석 (0) | 2023.02.09 |


