[KT AIVLE 3기] 시계열 데이터 처리
데이터 분석에서 흔히 시계열 데이터라는 말을 들을 수 있다.
시계열 데이터란 어떤 데이터를 의미할까?
행과 행 사이에 시간의 순서가 있고, 행과 행 사이 시간간격이 동일한 데이터를 "시계열 데이터"라 한다.
데이터 처리
시계열 데이터 처리를 연습해보자.
환경 준비
import pandas as pd
import numpy as np
판다스와 넘파이를 불러와준다.
sales = pd.read_csv("https://raw.githubusercontent.com/DA4BAM/dataset/master/ts_sales_simple.csv")
products = pd.read_csv("https://raw.githubusercontent.com/DA4BAM/dataset/master/ts_product_master.csv")
실습에서 사용할 데이터프레임을 불러와준다.
sales.info() / sales.head()
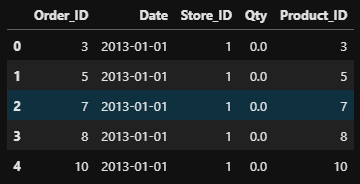
products.info() / products.head()

실습 1
Product_ID가 15인 것만 뽑아보자. 그러면 뭘 사용해야할까? -> loc
products.loc[products[Product_ID] == 20]
집계(groupby)도 한번 해볼까? Store_ID가 1인 것들 중에서, Product_ID 별로 Qty의 합을 알고싶어!
sales.loc[sales['Store_ID']==1].groupby('Product_ID', as_index = False)['Qty'].sum()
이번엔 병합해서 다뤄보자.
df = pd.merge(sales, products)
df['매출'] = df['Qty'] * df['Price'] # '매출' 이라는 열 생성 및 채우기
df를 Date, Category별로 집계하고, 매출의 합을 구해보자.
data1 = df.groupby(['Date', 'Category'], as_index = False)['매출'].sum()
pivot을 사용해서 구조를 변형시켜보자.
newdata = data1.pivot('Date', 'Category', '매출').reset_index() # Date: 인덱스, Category: 열, '매출': rkqt
newdata.head()
실습 2
날짜 요소를 추출하는 실습을 해보자. newdata에는 Date가 2013-01-01의 형식으로 표기되어 있다.
newdata['Date'] = pd.to_datetime(newdata['Date'])
newdata.info()
pd.to_datetime(date, format = '%d-%m-%Y') # format으로 날짜 데이터 형식을 알려주는 것연, 월, 일, 요일, 요일 이름을 추출해보자
date = newdata['Date']
# 연
date.dt.year
# 월
date.dt.month
# 일
date.dt.day
# 요일
date.dt.weekday
# 요일 이름
date.dt.day_name()
실습 3 - shift
시계열 데이터는 시간이 흐름에 따라 정보가 바뀌는데, 이에 따라 정보를 이동시킬 필요가 있을 때가 있다.
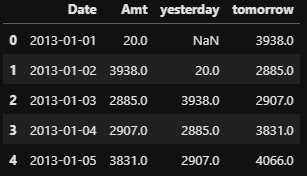
시계열 데이터에서 시간의 흐름 전후로 정보를 이동시킬 때 shift를 사용한다.temp = data.loc[:, ['Date', 'Amt']]
temp.head()

# 전날 매출액 열을 추가
temp['yesterday'] = temp['Amt'].shift() # shift default: 1
# 다음날
temp['tomorrow'] = temp['Amt'].shift(-1)
temp.head()
실습 4 - rolling
시간의 흐름에 따라 이동하면서 일정 기간 동안의 평균을 구하기 -> rolling + 집계함수
# 4일 이동평균 매출액을 구해보자
temp['Amt_7_1'] = temp['Amt'].rolling(4).mean() # 4일의 평균을 내는 거니까 ~3일까지는 평균값을 낼 수 없으므로, NaN이 뜰거다.
temp['Amt_7_2'] = temp['Amt'].rolling(4, min_periods = 1).mean()
temp.head()

실습 5 - diff
특정 시점 데이터와 이전시점 데이터와의 차이를 .diff()를 통해 구할 수 있다.
df.diff(periods=1, axis=0)
periods는 비교 기간(간격), axis = 0은 index, axis=1은 columns 의미
temp['diff1'] = temp['Amt'].diff()
temp['diff2'] = temp['Amt'].diff(2)
temp.head()

diff(2)의 경우 2칸씩 건너뛰어서 (1-3, 2-4) 차이를 보기 때문에 0, 1 인덱스가 NaN이 나오게 된다.
'AIVLE' 카테고리의 다른 글
| [KT AIVLE 3기] 단변량분석 (0) | 2023.02.09 |
|---|---|
| [KT AIVLE 3기] 데이터 시각화 (0) | 2023.02.09 |
| [KT AIVLE 3기] 데이터 처리 - day 1 (0) | 2023.02.08 |
| [KT AIVLE 3기] Python - Numpy & Pandas (0) | 2023.02.07 |
| [KT AIVLE 3기] Github vscode와 연동하기 (0) | 2023.02.02 |


