[KT AIVLE 3기] 단변량분석
이전에 배운 숫자형 / 범주형 변수를 통해 단변량분석을 배울 수 있다.
숫자형 변수는 min, max, mean, std, 사분위수 등으로 정리 -> Histogram, Density plot, Box plot 등으로 시각화
범주형 변수는 빈도 수 / 비율 등으로 정리 -> Bar plot / Pie chart 등으로 시각화
환경 준비
단변량 분석 실습에 필요한 환경을 세팅해보자.
먼저 라이브러리를 불러오자.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
필요한 데이터셋을 불러오자. 유명한 데이터셋인 타이타닉이다.
path = 'https://raw.githubusercontent.com/DA4BAM/dataset/master/titanic_simple.csv'
titanic = pd.read_csv(path)
titanic.head()

- Survived: 생존여부(0: 사망, 1: 생존)
- Pclass: 객실등급
- Embarked: 승선지역
숫자형 변수
수치화: 대푯값
titanic의 숫자형 변수들의 평균, 중앙값, 최빈값(빈도가 높은 값), 4분위수를 구해보자.
평균, 중앙값
# 넘파이 사용하기
np.mean(titanic['Fare']) # 32.2042079685746
np.median(titanic['Fare']) # 14.4542
# 판다스
titanic['Fare'].mean()
titanic['Fare'].median()
최빈값
titanic['Pclass'].mode() # 3
4분위수
titanic['Fare'].describe()
수치화: 기초통계량
Dataframe.describe()를 통해 숫자 타입 변수들의 기초통계량을 조회할 수 있다.
titanic.describe()
이 때, 데이터프레임의 전체 변수들의 기초통계량을 조회하고 싶다면 describe에 include='all'을 추가해주면 된다.
titanic.describe(include='all')
시각화
히스토그램
시각화에서 배운 히스토그램을 활용해보자.
# pyplot 사용
plt.hist(titanic.Fare, bins = 10, edgecolor = 'black') # bins: 간격
plt.xlabel('Fare')
plt.ylabel('Frequency')
plt.show()
# sns 사용
sns.histplot(x= 'Fare', data = titanic, bins = 10)
plt.show()
이 때, 결과를 변수에 저장하면 구간 및 빈도수를 확인할 수 있다.
히스토그램은 튜플로 저장된다. 한번 확인해보자.
a = plt.hist(titanic.Fare, bins = 10, edgecolor = 'black')
print(a)
print(type(a))
print("a[0]: ", a[0])
print("a[1]: ", a[1])
밀도함수
히스토그램은 구간의 너비(bin)에 따라 모양이 달라진다.
즉, 막대의 너비를 정한 채로 plot하기보다는 모든 점에서 데이터의 밀도를 추정하는 방식(Kernel Density Estimation)이 필요할 때가 있다.
kde 방식의 밀도함수 그래프를 그려보자.
sns.kdeplot(titanic['Fare'])
plt.show()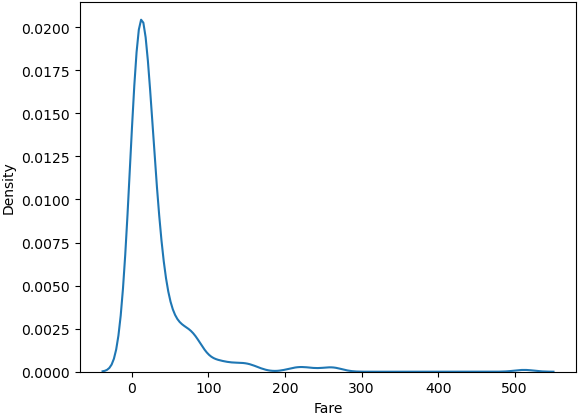
히스토그램과 kde 간의 비교를 해볼까?
plt.subplot(2,1,1)
plt.hist(titanic.Age, bins = 5)
plt.subplot(2,1,2)
sns.kdeplot(titanic.Age)
plt.show()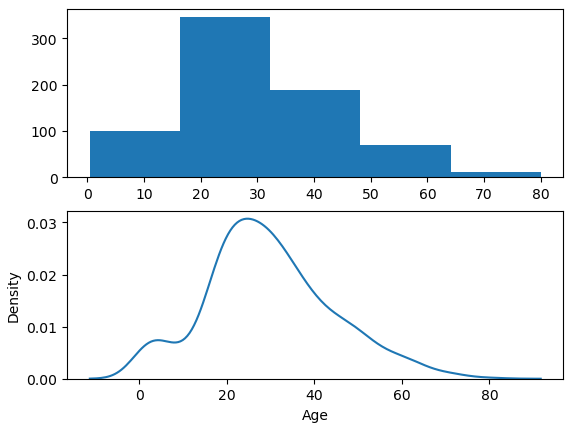
Boxplot
주의: 값에 NaN이 있으면 그래프가 그려지지 않는다.
titanic.info()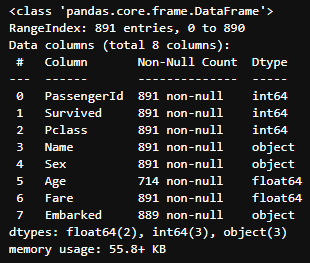
NaN을 제외한 데이터를 따로 빼주려면 -> loc
temp = titanic.loc[titanic['Age'].notnull()]이제 boxplot을 그려보자.
plt.boxplot(temp['Age'], vert = False) # vert = vertical
plt.grid()
plt.show()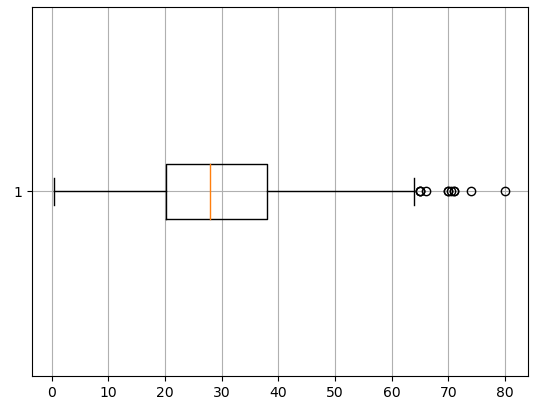
범주형 변수
범주형 변수는 숫자형 변수와 다르다는 것을 앞에서 배웠다.
수치화: 기초통계량
범주별 빈도수, 비율을 확인해보자.
List.count('값')을 통해 해당 값이 몇 개 있는지 확인할 수 있고, 이를 전체 개수로 나눠주면 비율이 된다.
하지만 범주가 너무 많다면? 이걸 하나하나 다 할 시간이 있을까?
범주별 빈도 수
.value_counts(): 범주 개수와 상관없이 범주 별 개수를 세준다.
titanic['Embarked'].value_counts()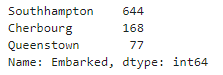
범주별 비율
.value_counts()를 전체 데이터 건수로 나눠준다.
이 때, 전체 데이터 건수는 .shape[0]으로 구할 수 있다.
print(titanic.shape)
titanic['Embarked'].value_counts()/titanic.shape[0]
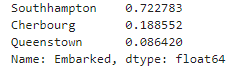
탑승지 중 Queenstown이 0.08, Cherbourg가 0.18, Southhampton이 0.72 정도의 비율을 차지한다.
시각화
Bar chart
집계 후 그래프를 그려야 하는데, seaborn의 countplot은 집계 + bar plot 역할을 한다.
sns.countplot(titanic['Embarked'])
plt.grid()
plt.show()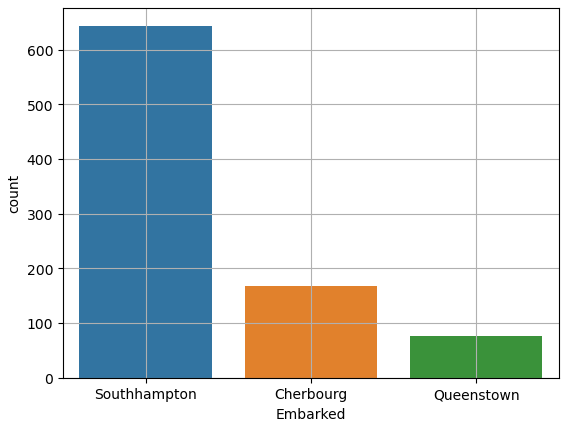
Pie chart
파이 차트는 범주 별 비율을 비교할 때 주로 사용한다. 역시 집계가 먼저겠지?
plt.pie(값, labels = 범주이름, autopct = '%.2f%%') -> 2f% = 소수점 두 자리까지
temp = titanic['Embarked'].value_counts()
plt.pie(temp.values, labels = temp.index, autopct = '%.2f%%')
plt.show()
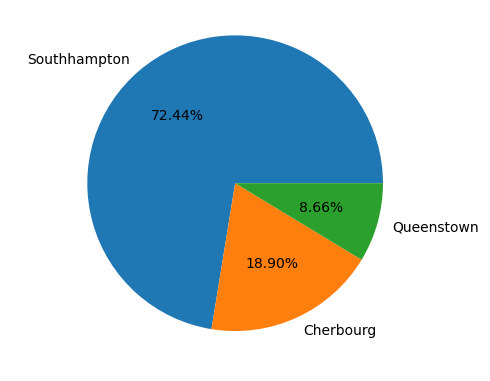
꾸미는 것도 있긴 한데 필요하면 찾아서 하는 걸로...
'AIVLE' 카테고리의 다른 글
| [AIVLE] 머신러닝 (0) | 2023.02.24 |
|---|---|
| [KT AIVLE 3기] 이변량분석 (0) | 2023.02.10 |
| [KT AIVLE 3기] 데이터 시각화 (0) | 2023.02.09 |
| [KT AIVLE 3기] 시계열 데이터 처리 (0) | 2023.02.09 |
| [KT AIVLE 3기] 데이터 처리 - day 1 (0) | 2023.02.08 |



